爬虫工程师介绍
爬虫工程师指的是通过编写程序获取互联网中的信息。例如:爬取豆瓣的top250电影列表,定时某个城市天气预报详细信息,获取金融街当日所有股票的实时行情等。爬取的数据可以通过聚合为用户提供服务。
爬虫工作师可以用各种语言去实现,这里只介绍Python爬虫工程师的原因:Python易学性,爬虫相关第三方包很多(例如scrapy,requests, aiohttp等)。
爬虫工程师的主要工作技能包括以下(不限于)
- Python语言(至少需要熟悉多线程,多进程,性能变态需要了解异步编程)
- BeautifulSoup、re、lxml、requests等相关Python包使用
- MySql,MongoDB, Oracle, SQL Server 至少熟悉其中一种
- Redis 方便进行分布式爬取数据
- Linux操作系统了解(熟悉编译安装程序,了解yum/apt,Linux基本操作,Shell)
- Fiddler抓包基础(至少学会使用Fiddler解密https,使用Fiddle代理抓取手机/其他设备的数据包。 也可以使用其他工具)
- Chrome浏览器控制台基本使用
- webdrive 模拟浏览器使用
- Javascript解密
- App解密
基础入门资料
推荐指数:5星,强烈推荐入门可以多读几遍,加深理解
推荐指数:4.5星,可以阅读廖雪峰教程之后进行基础知识的查缺补漏
推荐指数:5星,一般抓取网页数据用chrome抓包基本可以满足使用,移动端可以用fiddler抓包
推荐指数:5星,小白入门SQL必备书籍,可以抽1-2天时间通读一遍之后安装MySQL进行练习
推荐指数:4星,主要用于电脑上临时编写SQL查阅使用
推荐指数:5星,入门必看,看完之后务必做大量的练习
推荐指数:4星,了解redis
推荐指数:5星,主要是通过Python语言操作数据库
学习指导(满满干货)
第一次学习编程语言的同学,建议先花1~2周时间通读一遍廖雪峰Python教程,部分内容看不懂的可以跳过,等基础入门后再来回读下,第一遍看完以后,至少已经知道熟练使用下面这些知识点:
- 数据类型和变量的用法
- 熟练使用字符串的各类用法,熟悉字符串的基本概念
- 熟练使用list, dict用法(定义、切片、更新、删除)
- 熟练书写if判断语句
- 熟练使用for,while循环
- 熟练定义函数,调用函数,函数的参数要理解透彻(递归函数可以跳过)
- 熟练通过pip安装第三方模块、导入第三方模块、调用第三方模块函数(强烈推荐使用requests模块练习,因为中文文档写的很详细),并同时熟悉模块BeautifulSoup、re,json。
- 熟练使用try…except…finally… 使用
- 熟练文件读写、操作目录
- 熟练使用正则表达式(可以通过在线网站测试正则表达式)
学习上面的基础知识之后,了解下chrome控制台network抓包工具使用,就可以编写最简单的爬虫(不包含更新、存储逻辑、反爬虫机制等)。
最简单的几个爬虫实例详解
例子1:通过已有天气api接口获取
https://www.sojson.com/open/api/weather/json.shtml?city=武汉
先通过chrome浏览器–>F12抓包看下
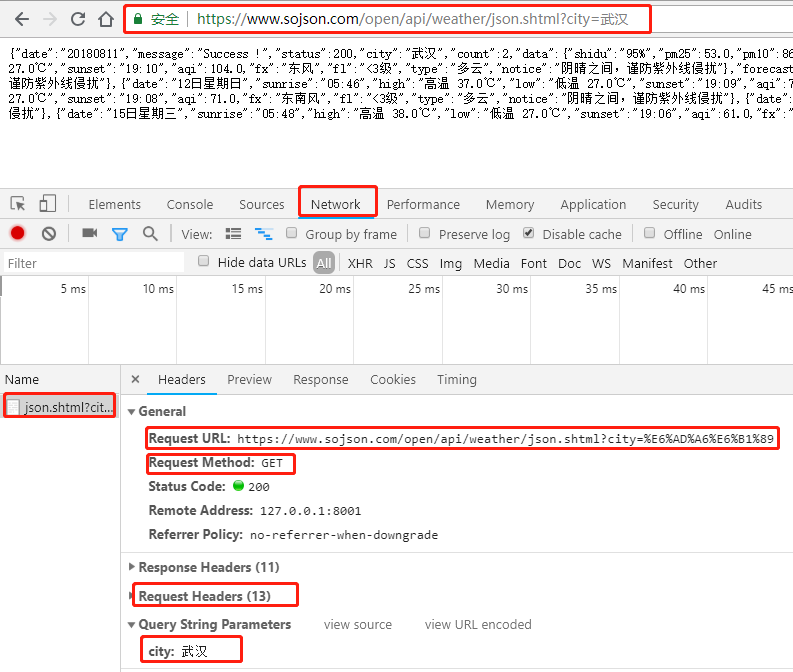
我们通过network可以看到发送请求的url对应Request URL :https://www.sojson.com/open/api/weather/json.shtml?city=%E6%AD%A6%E6%B1%89
发送请求的方法对应Request Method :GET
发送请求的Headers对应Request Headers:太多了这里不写了
发送请求的参数为Query String Parameters: city:武汉
代码如下:
import requests
import json
url = "https://www.sojson.com/open/api/weather/json.shtml?city={}"
def get_weather(city):
"""
通过参数city获取不同城市天气
:param city: 城市
:return: 天气详细信息的字典
"""
res = requests.get(url=url.format(city))
print(json.loads(res.text))
if __name__ == '__main__':
get_weather("武汉")
例子2:登录光谷社区
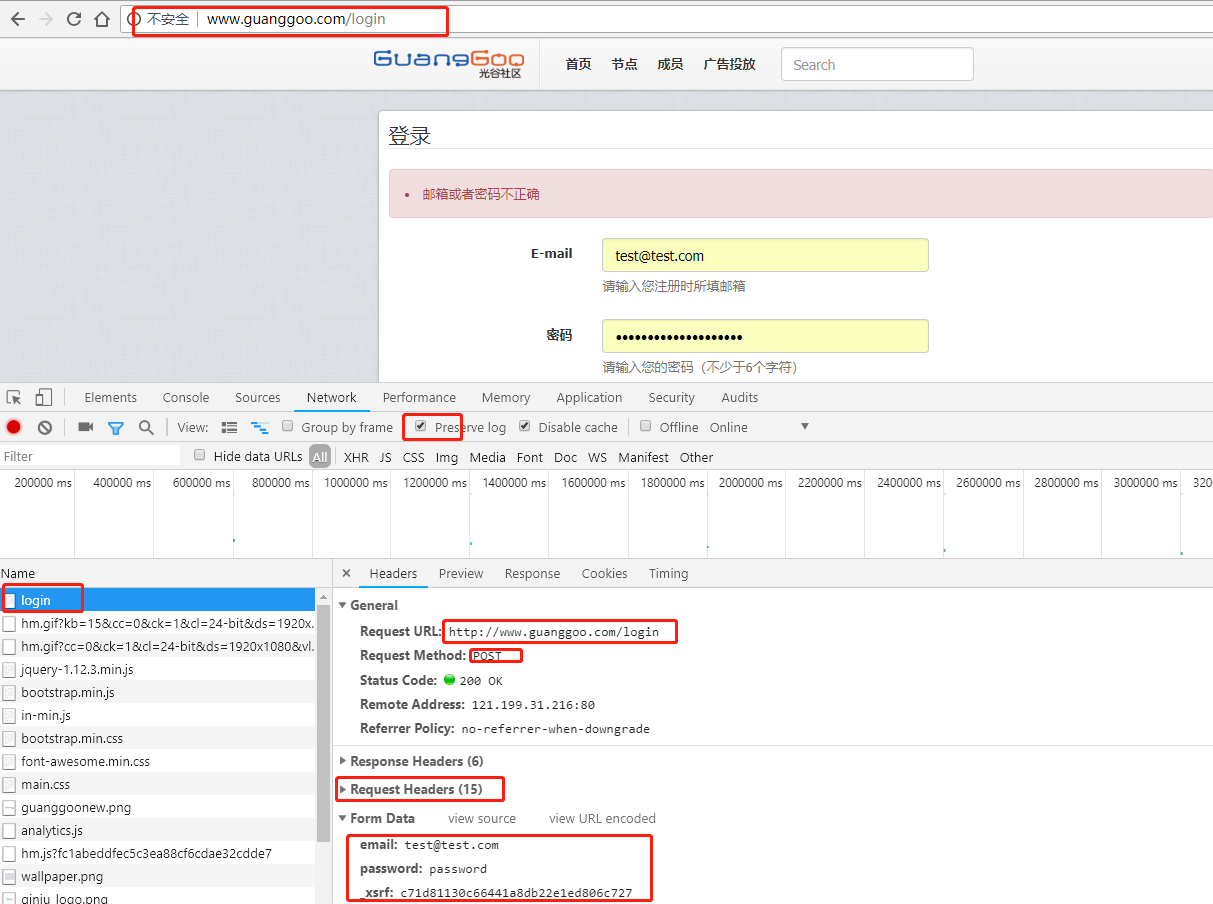
有一个_xsrf参数可以通过chrome工具中Elements中CTRL+F 查找
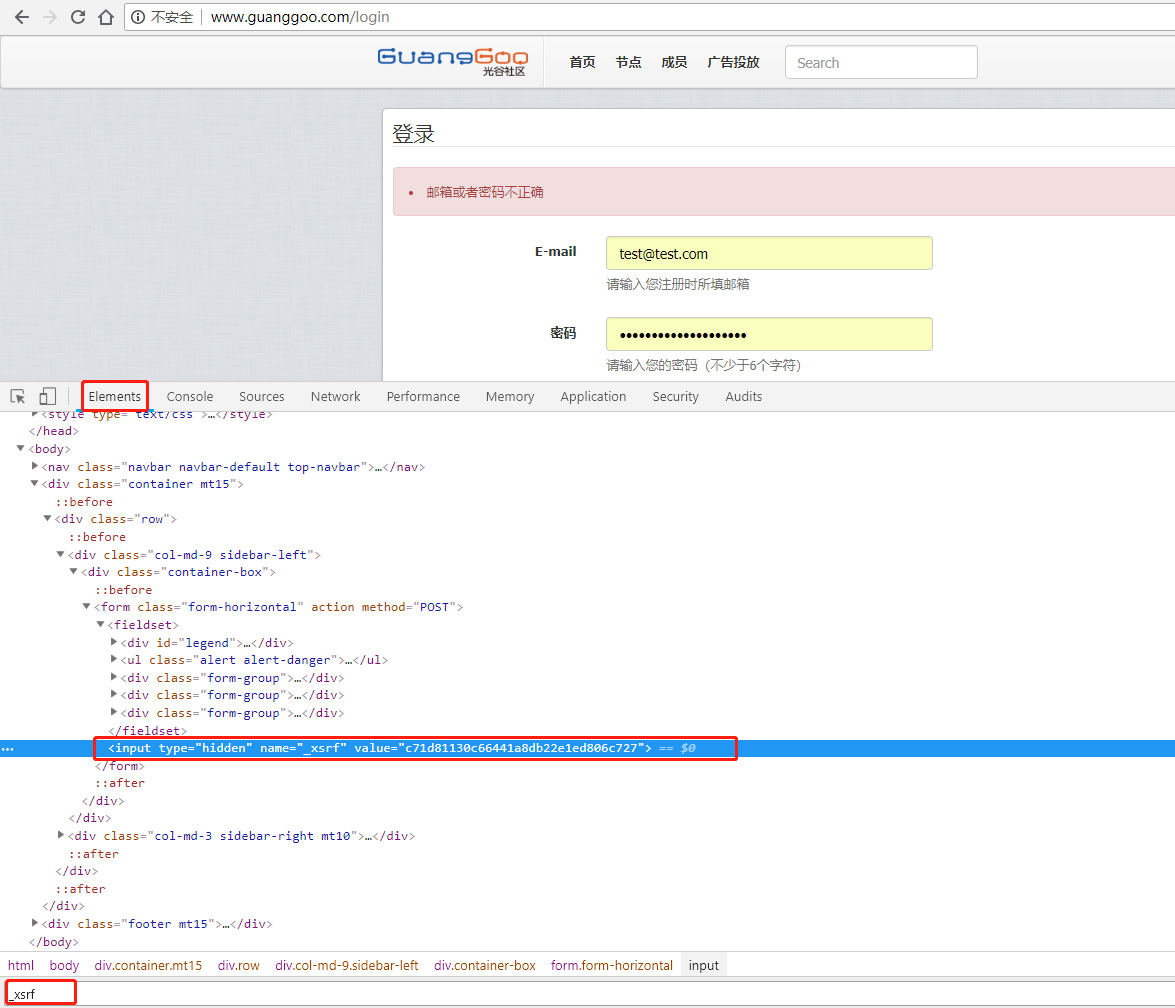
实例代码如下:
import requests
from bs4 import BeautifulSoup
session = requests.session()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
}
login_url = "http://www.guanggoo.com/login"
def login(user, password, xsrf):
"""
登陆光谷社区请求函数
:param user: 用户名
:param password: 加密后的密码
:param xsrf: 前端验证码
:return: True/False
"""
data = {
"email": user,
"password": password,
"_xsrf": xsrf,
}
res = session.post(login_url, data=data, headers=headers)
if res.history and res.history[0].status_code == 302:
print("登陆成功")
return True
else:
print("登陆失败")
return False
def parse_xsrf():
"""
获取登陆过程中参数_xsrf的值
:return:
"""
res = session.get(login_url, headers=headers)
if res.status_code != 200:
print("获取xsrf失败")
raise requests.RequestException
soup = BeautifulSoup(res.text, "html.parser")
result = soup.find("input", attrs={"name": "_xsrf"}).get("value")
return result
def get_information():
"""
通过访问用户中心判断是否登陆成功,如果没有登陆的用户,访问用户中心会直接跳转到登陆界面
:return:
"""
information_url = "http://www.guanggoo.com/setting"
res = session.get(information_url, headers=headers)
soup = BeautifulSoup(res.text, "html.parser")
result = soup.find("input", id="username")
if result:
print("获取用户名成功,username:[{}]".format(result.get("value")))
else:
print("获取用户名失败,可能前面登陆过程没有成功")
if __name__ == '__main__':
user = input("请输入用户名:")
password = input("请输入加密后的密码:")
code = parse_xsrf()
login_result = login(user, password, code)
get_information()
请参阅代码后,独立写一遍检查能否完成,如果没有完成,请细读上面的代码。如果能独立完成上面代码,请完成课后作业
爬取http://www.guanggoo.com/?p=1前三页帖子信息并将相关信息写入到excel中(可以使用openpyxl模块操作excel)

字段要求:
- 标题名称: title(字符型)
- 所属节点: node(字符型)
- 发布帖子用户名: post_user(字符型)
- 发布时间: post_time(datetime/字符型)
- 最后回复用户名: last_user(字符型)
- 回复数: reply_num(整数型)
完成后请上传excel至网盘,评论回复网盘链接
上面的介绍的只是基础,未完待续@_@,不定期更新高级内容
